Jan. 12, 2024
In 1945 the volume of human knowledge doubled every 25 years. Now, that number is 12 hours [1]. With our …
April 21, 2023
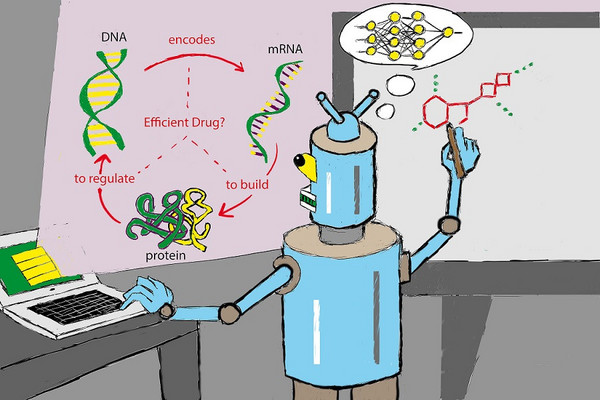
The terms “big data”, “machine learning”, and “artificial intelligence” have been trending in the AI drug discovery space for several …
July 15, 2021
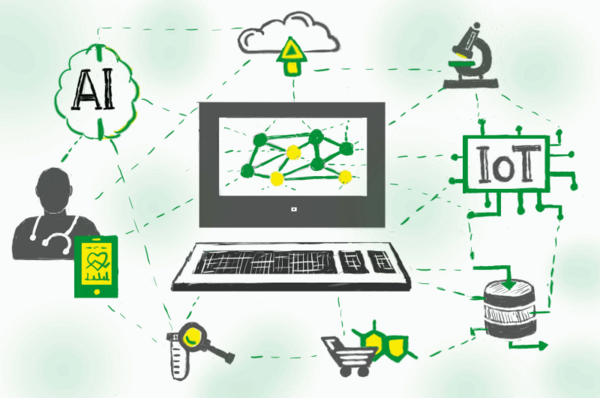
The future of the connected world is not just about the newest frontier technologies, such as high-band 5G. It will …
March 15, 2021
Covid-19 is still having a devastating effect on many countries and economies worldwide and has brought to light the impact …
Sept. 25, 2020
Founded by renowned database researcher, Turing Award laureate MIT Professor Michael Stonebraker, Paradigm4 is not just any data analytics company …
Feb. 4, 2020
Chemical Data Has Problems The state of data access, quality and dissemination in Chemistry is extremely poor - so poor …
July 22, 2019
In today’s technological world, data is perhaps the single most important driver of a business’ success. Access to relevant data …
July 2, 2019
Chemical data management is an important process to a number of industries, especially those engaged in manufacturing or research and …
Feb. 20, 2019
In 1970-80s, the idea of virtual screening was regarded as a conceptual way to substitute costly and time-consuming experimental “screen-everything-you-have” …
Jan. 10, 2019
Updated: 10.01.2019. Newly added content is marked in the text with "Update" sign. The idea of using artificial intelligence (AI) …
Dec. 19, 2018
Over the last five years the interest of pharmaceutical professionals towards machine learning (ML) and artificial intelligence (AI) has measurably …
Sept. 27, 2018
What is a super-platform? A “super-platform” is a term which describes a relatively new phenomenon in a modern technological world …




![[Interview] A New Way To Work …](/files/blog/post-2020-09-25.jpg)