Introducing Intelligent Platform For Document Review And Automated Data Extraction
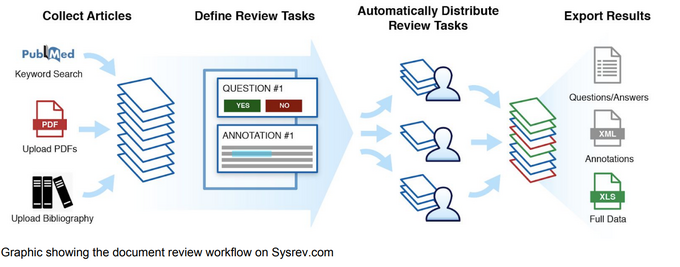
In today’s technological world, data is perhaps the single most important driver of a business’ success. Access to relevant data allows businesses to make a variety of informed decisions. Unfortunately, acquiring this data can be quite cumbersome as employees spend countless hours manually reviewing documents. This is especially true for more complex reviews such as journal publications, patient records, or technical specifications. Sysrev offers enterprise a platform for managing collaborative document reviews, injecting machine learning into the review process to increase accuracy and efficiency. Depending on the data source and task, Sysrev can even automate data extraction.
Sysrev, launched in June 2019, is an intelligent platform for document reviews and automated data extraction. Sysrev optimizes the review process with machine learning and adds efficiency through its intuitive, and collaborative, interface.
Topics: AI & Digital
