Navigating the Crossroads of AI and Oncology: A Deep Dive with Lantern Pharma's CEO, Panna Sharma
The development of oncology drugs faces significant challenges, including a high failure rate (97%) in clinical trials, due to complex genetic interactions, emerging drug resistance, and limitations in preclinical models.
Clinical trial designs often lack specificity, failing to consider genetic factors unique to cancer types, resulting in trials without biomarker integration being 12 times more likely to fail.
To address these issues, Dallas-based Lantern Pharma (NASDAQ: LTRN) utilizes the RADR® AI platform, which applies machine learning to analyze genomic and transcriptomic data, enhancing the understanding of drug mechanisms, identifying patient-specific therapeutic responses, and optimizing clinical trial designs.
In this deep dive interview, Panna Sharma, the CEO of Lantern Pharma, offers an insightful look into the company's progression in the challenging fields of cancer research, drug discovery, and the use of artificial intelligence. Sharma, with his diverse background that includes leading a cancer diagnostics company and a stint in investment banking, discusses Lantern Pharma's expansion from a small, budding team to a formidable force in the oncology sector, now managing 14 cancer indications and advancing three drugs into clinical trials.
He highlights pivotal moments in his career, such as taking Cancer Genetics public in 2013 and joining Lantern Pharma in 2018, leading up to a successful public fundraising effort in mid-2020 that raised about $96 million. The conversation also ventures into the establishment of Starlight Therapeutics, focused on brain cancer research.
Note: the following is an automatically generated transcript from a video interview you can watch it on our new YouTube channel. While the transcript was edited for clarity and style, it may still contain colloquial sentences and expressions.
Andrii: Panna, can you please introduce yourself a little bit and tell us about your journey in this field, how you became the leading figure of Lantern Pharma and why you actually choose this intersection of cancer research, drug discovery, and artificial intelligence?
Panna: Thank you for having me, Andrii. It's been really a pretty remarkable few years since I've been at Lantern. I joined the company about five years ago now. It was a small company, a handful of people, probably count on one hand. And I joined because I really felt that there was a chance to use data-driven approaches to drug development. That's what excited me.
 My background, prior to that, I was running another cancer company, mostly doing diagnostic and companion diagnostic clinical service work for big pharma companies and also for end patients. And so I saw the power of using biomarkers and genomic guided medicine hands-on.
My background, prior to that, I was running another cancer company, mostly doing diagnostic and companion diagnostic clinical service work for big pharma companies and also for end patients. And so I saw the power of using biomarkers and genomic guided medicine hands-on.
You know, I led pretty big teams where we did a lot of development of companion diagnostics for lots of different cancer drugs, antibodies, small molecules, combination regimens. And it was both interesting but also frustrating because you saw a lot of times that drug development wasn't using the exact data they were paying for. But you could see that how data was able to guide to more successful potential outcomes in narrower populations.
And as I looked more deeply into that, I said, you know, the next company I really want to be able to use all this amazing data that's getting generated. And prior to running that cancer company, Cancer Genetics, I was actually, I took that company public back in 2013. I came to Lantern in 2018. I took it public in middle of 2020, raised about $96 million publicly, raised a few million also privately. And it was a perfect intersection of my interest in cancer research, where I spent a lot of time.
I was also a managing member of a joint venture with the Mayo Clinic, actually with their center for individualized medicine and, learn a lot hands on there with some of the top minds in cancer research and a company called the OncoSpire where we're developing kind of breakthrough new diagnostic paradigms to guide a lot of these precision oncology drugs.
And then prior to that, I was an investment banker, fortunately, in life science and biotech. And I got to see a lot of companies hands on, you know, the growth of companies, the funding of companies, the challenge of going from early stage to mid-stage, the challenges of late stage trying to continue to be innovative. So a lot of great experience and exposure to a lot of wonderful companies. And with each one I was learning lesson about, you know, what I enjoyed personally, but also what was making certain companies vulnerable versus making them successful from a business perspective. And actually I started my career, ironically enough, believe it or not, Andrii, in AI, actually back in 1992, 1993 when I graduated.
So this was a long time ago. It was nothing like where it is today, but I actually studied AI neural network theory in college, believe it or not. To me, it was like a perfect blending of all the different skills that are needed to really be where we are today, which is appreciation and network in the cancer field where there's tremendous need for new medicines.
At Lantern, we didn't have a billion dollars, but we had some good ideas and we had the ability to develop an engine to look at very, very specific problems in cancer. And I had the background to help think and guide some of the business decisions. So I came on about five years ago. I think we have a fantastic team that has gone from one indication to now 14 indications.
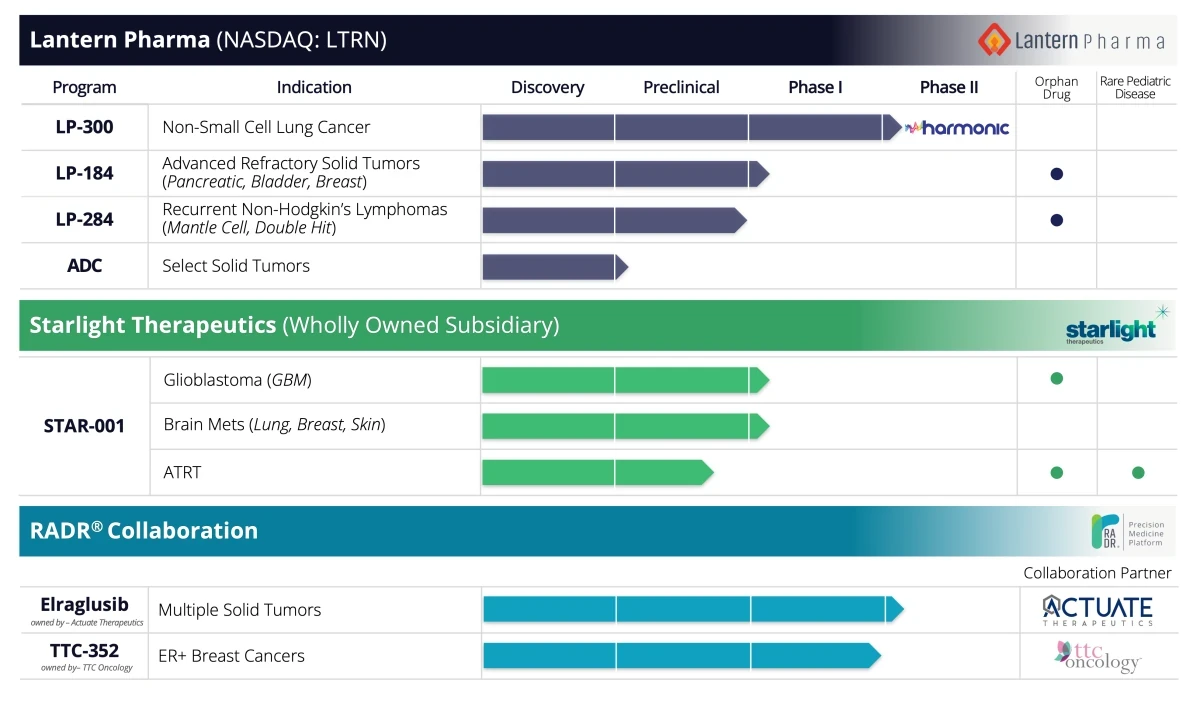
We've got three drugs in clinical trials now. So probably very, very high percentage of programs actually touching patients. We're dosing patients in multiple trials with three different drugs across many indications. And so we're pretty excited by that. And this is all because of the power of using data and AI-driven drug development.
READ ALSO: How AI Enables Precision Oncology
Andrii: That sounds really like you have a sweet spot in terms of skill sets to run this company. Let's unpack this a little bit. As a guy with the actual business background as well, not only scientific background, can you share your framework for building a biotech company, especially clinical biotech company.
Maybe you can share in your example of how Lantern was built, why it is growing, how you managed to pull this off in terms of business. Because science is a great thing, and we will come back to it later in much more detail, but how did you manage to run and grow the company?
Panna: A lot of it is planning, a lot of it is luck, a lot of it is also your own network. I don't know if there's any magic button you can press. You know, we were fortunate to be in funding mode at a time when there was a lot of funding available for biotech, you know, right after the pandemic, there was a real interest in all things biotech. So we were able to hit the market at the right time.
And we made some of the good decisions. We had a lot of decisions to take money privately versus publicly. And I think at the time, the cost of capital for us publicly and the amount of control that we could exert over the business publicly versus privately was better for us. And I remember that was a real moment when we got to sit down and say, okay, we're gonna take a public round, which looks maybe iffy, but it looks positive, or are we gonna take a much smaller, potentially at the time, much more dilutive private round?
We also had a lot of really good, smart advisors and that really helped. And I had wonderful bankers and lawyers that I worked with over the years. So, you know, you got to take lots of input as CEO. You're gonna take a lot of input and you're gonna read the cards of what's going on in the market.
But ultimately you have to have that expectation of, where is this funding going to take us? Because interesting science takes big funding. It takes big funding and it takes the ability to make decisions that can be really, really tough. So you wanna make sure that whatever decisions you're making, you're not gonna lose your focus on the end goal and make sure that people that are lined up with you, in trying to drive that shareholder value or build the base of value are going to be mindful of what the end goal is because if you don't have that then you're going to run into challenges and that's across any company not just biotech.
Andrii: Good points! My career started as a researcher and I have seen so many academic labs which would produce some kind of cool results. But then when they would start an actual spin-off, or a VC startup, they would never take off for some reason. And so I realized that it is so important to take care about the business side, the financials, all these kind of organizational aspects versus just cool science.
Panna: Yeah, you got to do both. You know, you can't have mediocre science and really good business and expect it to be a winning equation. It can be, but it's not guaranteed. And you can't really have mediocre business and great science. So you got to really try to bring both together. And then the timing has to be right. We really are at a time where I think even big pharma really sees that.
AI and computationally driven approaches to drug development are making a difference. You know, they haven't jumped in 100%, but they're all dipping their toes in the water. But even in this space, you know, there are a lot of, I would say, there are a lot of little favorites, you know, so I always think innovation really is going to come from the outside. And if you look at industries like finance and semiconductors and tech, they have different regulatory pressures than of course drug development. But a lot of that innovation, it didn't come from inside the four walls of all the big companies, it came from outside. And so I think we're beginning to see people accepting AI, but it's still somewhat muted. They want their own people doing the AI. They want their own ex-executives running their companies. That's what they're comfortable with.
But really, I think we're at the very early stages of AI just transforming this industry. We can't have 400 or 500 different cancer types that we know and only 90 drugs. So there's a wide open space. And so I think we really want to shape Lantern to try to be a pioneer in the rapid development of therapies, cancer therapies, with some novel data and AI driven approaches.
And where we are today is so different for a small company than where we were even three years ago versus five years ago. The computational power of things that we can do today is just continues to increase. And when we can look at thousands and thousands of molecules in an afternoon and characterize them and generate new molecular features on them in a matter of hours that, you know, things you couldn't even imagine doing some 10 years ago.
So this kind of improvement in output yields improvement in the cost structure of developing drugs. And it also improves the ability to make more, I would say, precise and guided design of validation experiments in animals and eventually going to trials.
And so this is really important because then all that data comes back to the life cycle management of that molecule. Thinking about new indications, thinking about combinations, all that stuff is very important. And the earlier you can determine that in the development of the molecule or the drug, you know, I think the greater confidence you'll have when talking with pharma partners, but also with your investors. And that really hasn't happened until very recently.
Oftentimes you'll even see, even when we look at historical trials of some compounds, you'll see people went head first into phase one or phase one B, and they really didn't fully understand the molecule yet, which is surprising to me. And so now that's changing. You're seeing companies like ourselves and other great AI driven companies that they really understand the molecular features, mechanisms of action, potential combinations, much earlier in the life cycle of the program, which is, I think, really needed.
Topics: AI & Digital