19 Companies Pioneering AI Foundation Models in Pharma and Biotech
Foundation models represent a new paradigm in artificial intelligence (AI), revolutionizing how machine learning models are developed and deployed. As these models grow increasingly capable, they become useful for applications across a wide range of economic functions and industries, including biotech. Foundation models are a class of large-scale machine learning models, typically based on deep learning architectures such as transformers, that are trained on massive datasets encompassing diverse types of data. The most prominent examples of general-purpose foundation models are the GPT-3 and GPT-4 models, which form the basis of ChatGPT, and BERT, or Bidirectional Encoder Representations from Transformers. These are gigantic models trained on enormous volumes of data, often in a self-supervised or unsupervised manner (without the need for labeled data).
Their scalability in terms of both model size and data volume enables them to capture intricate patterns and dependencies within the data. The pre-training phase of foundation models imparts them with a broad knowledge base, making them highly efficient in few-shot or zero-shot learning scenarios where minimal labeled data is available for specific tasks.
This approach demonstrates their high versatility and transfer learning capabilities, adapting to the nuances of particular challenges through additional training.
Below we summarized a number of companies building domain-specific foundation models for biology research and related areas, like chemistry.
Atomic AI
Atomic AI, a biotech company focused on AI-driven RNA drug discovery, aims for atomic precision in their work. Their proprietary platform, PARSE (Platform for AI-driven RNA Structure Exploration), is based on a machine learning model trained on a limited set of RNA molecules.
This model makes accurate predictions about the structure of various RNA molecules, enhancing RNA structure prediction. Atomic AI utilizes their foundational model internally for their drug discovery program, enabling them to pursue novel targets in RNA that were previously inaccessible. This approach aligns with the pharmaceutical industry's growing interest in novel biology, facilitating new avenues in drug discovery.
BioMap
BioMap focuses on unveiling nature's rules and generating diverse proteins with high accuracy. Their primary foundation model, xTrimo (Cross-Modal Transformer Representation of Interactome and Multi-Omics), is designed to understand and predict life's behavior at various complexity levels. xTrimo is trained on extensive datasets, including over 6 billion proteins and 100 billion protein-protein interactions, making it the largest life science AI foundation model with over 100 billion parameters.
This model's scale allows it to inform multiple downstream task models even with minimal data. BioMap’s strategic collaboration with Sanofi, announced in 2023, involves co-developing AI modules for biotherapeutic drug discovery, leveraging BioMap’s AI expertise and Sanofi’s proprietary data to create advanced AI models for biologics design and optimization.
Bioptimus
In February 2024, Bioptimus, a biotech startup based in France, announced the successful closure of a $35 million seed funding round to develop an AI foundation model targeting advancements across the biological spectrum, from molecular to organismal levels.
Led by Professor Jean-Philippe Vert, the company collaborates with Owkin to leverage extensive data generation capabilities and multimodal patient data from leading academic hospitals worldwide. Owkin's initiative, MOSAIC, represents one of the largest multi-omics atlases for cancer research, showcasing the potential of combining computational and experimental research methods.
This collaboration, supported by Amazon Web Services (AWS), is crucial for developing AI models capable of capturing the diversity of biological data.
Chai Discovery
Chai Discovery, a six-month-old AI biology startup based in San Francisco, just announced the release of its first open-source model, Chai-1. The model is designed to predict the structure of biochemical molecules, a key capability in drug discovery.
The company, founded by former OpenAI and Meta researchers, recently raised nearly $30 million in a seed funding round led by Thrive Capital and OpenAI, valuing the company at $150 million. Chai Discovery is focused on using AI foundation models to transform biology from a science into an engineering discipline, with a particular emphasis on predicting and reprogramming molecular interactions.
Chai-1 is an advanced AI model that predicts the structures of various biochemical entities, such as proteins, small molecules, DNA, RNA, and even complex chemical modifications. What sets Chai-1 apart from other tools, like Google DeepMind’s AlphaFold, is its ability to achieve higher accuracy in predicting these structures, with improvements of 10% to 20% in success rates on key tasks related to drug discovery.
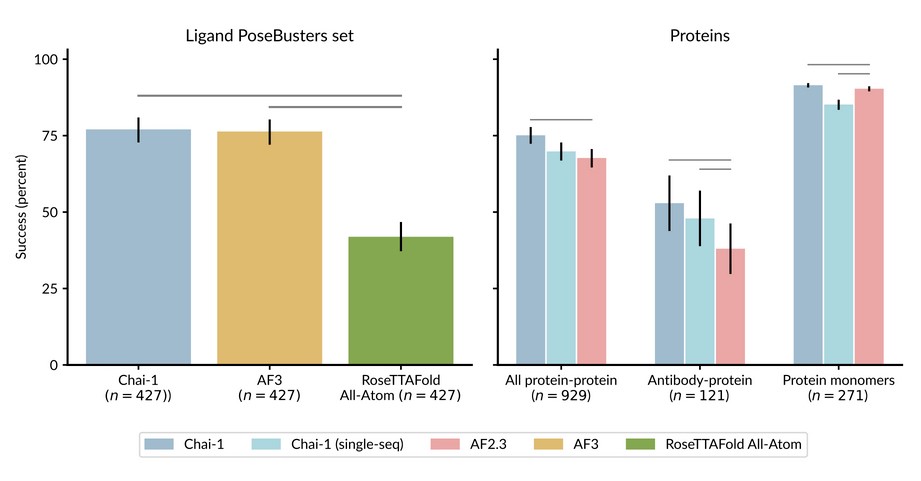
Chait-1 benchmark test results
For example, Chai-1 has shown a 77% success rate on the PoseBusters benchmark, which is a test that measures how well the model can predict how proteins and other molecules fit together—a crucial step in designing new drugs. It also scored 0.849 on the CASP15 protein monomer structure prediction set, which means it’s very good at accurately predicting the shape of single proteins, outperforming other top models.
The key thing about Chai-1 is that it doesn’t rely on a method called multiple sequence alignments (MSAs), which most traditional models use to find patterns in sequences of proteins or other molecules. MSAs require lots of data and computational power, which can be a bottleneck. Instead, Chai-1 can work with just a single sequence of a molecule and still make highly accurate predictions. This makes it much more versatile and efficient, especially in situations where data is scarce or incomplete—common challenges in real-world drug discovery.
In simpler terms, Chai-1 can take a simpler input and still deliver top-notch results, making it a powerful tool for researchers aiming to speed up the process of finding new medications.
The model’s practical applications are vast, as it enhances drug discovery processes by providing precise predictions of molecular structures and interactions. Chai-1 is particularly effective at predicting protein-ligand interactions and folding multimers, achieving higher accuracy than MSA-based models.
Continue reading
This content available exclusively for BPT Mebmers
We use cookies to personalise content and to analyse our traffic.
You consent to our cookies if you continue to use our website. Read more details in our
cookies policy.