Sponsored by Lantern Pharma
Navigating the Crossroads of AI and Oncology: A Deep Dive with Lantern Pharma's CEO, Panna Sharma
The development of oncology drugs faces significant challenges, including a high failure rate (97%) in clinical trials, due to complex genetic interactions, emerging drug resistance, and limitations in preclinical models.
Clinical trial designs often lack specificity, failing to consider genetic factors unique to cancer types, resulting in trials without biomarker integration being 12 times more likely to fail.
To address these issues, Dallas-based Lantern Pharma (NASDAQ: LTRN) utilizes the RADR® AI platform, which applies machine learning to analyze genomic and transcriptomic data, enhancing the understanding of drug mechanisms, identifying patient-specific therapeutic responses, and optimizing clinical trial designs.
In this deep dive interview, Panna Sharma, the CEO of Lantern Pharma, offers an insightful look into the company's progression in the challenging fields of cancer research, drug discovery, and the use of artificial intelligence. Sharma, with his diverse background that includes leading a cancer diagnostics company and a stint in investment banking, discusses Lantern Pharma's expansion from a small, budding team to a formidable force in the oncology sector, now managing 14 cancer indications and advancing three drugs into clinical trials.
He highlights pivotal moments in his career, such as taking Cancer Genetics public in 2013 and joining Lantern Pharma in 2018, leading up to a successful public fundraising effort in mid-2020 that raised about $96 million. The conversation also ventures into the establishment of Starlight Therapeutics, focused on brain cancer research.
Note: the following is an automatically generated transcript from a video interview you can watch it on our new YouTube channel. While the transcript was edited for clarity and style, it may still contain colloquial sentences and expressions.
Andrii: Panna, can you please introduce yourself a little bit and tell us about your journey in this field, how you became the leading figure of Lantern Pharma and why you actually choose this intersection of cancer research, drug discovery, and artificial intelligence?
Panna: Thank you for having me, Andrii. It's been really a pretty remarkable few years since I've been at Lantern. I joined the company about five years ago now. It was a small company, a handful of people, probably count on one hand. And I joined because I really felt that there was a chance to use data-driven approaches to drug development. That's what excited me.
 My background, prior to that, I was running another cancer company, mostly doing diagnostic and companion diagnostic clinical service work for big pharma companies and also for end patients. And so I saw the power of using biomarkers and genomic guided medicine hands-on.
My background, prior to that, I was running another cancer company, mostly doing diagnostic and companion diagnostic clinical service work for big pharma companies and also for end patients. And so I saw the power of using biomarkers and genomic guided medicine hands-on.
You know, I led pretty big teams where we did a lot of development of companion diagnostics for lots of different cancer drugs, antibodies, small molecules, combination regimens. And it was both interesting but also frustrating because you saw a lot of times that drug development wasn't using the exact data they were paying for. But you could see that how data was able to guide to more successful potential outcomes in narrower populations.
And as I looked more deeply into that, I said, you know, the next company I really want to be able to use all this amazing data that's getting generated. And prior to running that cancer company, Cancer Genetics, I was actually, I took that company public back in 2013. I came to Lantern in 2018. I took it public in middle of 2020, raised about $96 million publicly, raised a few million also privately. And it was a perfect intersection of my interest in cancer research, where I spent a lot of time.
I was also a managing member of a joint venture with the Mayo Clinic, actually with their center for individualized medicine and, learn a lot hands on there with some of the top minds in cancer research and a company called the OncoSpire where we're developing kind of breakthrough new diagnostic paradigms to guide a lot of these precision oncology drugs.
And then prior to that, I was an investment banker, fortunately, in life science and biotech. And I got to see a lot of companies hands on, you know, the growth of companies, the funding of companies, the challenge of going from early stage to mid-stage, the challenges of late stage trying to continue to be innovative. So a lot of great experience and exposure to a lot of wonderful companies. And with each one I was learning lesson about, you know, what I enjoyed personally, but also what was making certain companies vulnerable versus making them successful from a business perspective. And actually I started my career, ironically enough, believe it or not, Andrii, in AI, actually back in 1992, 1993 when I graduated.
So this was a long time ago. It was nothing like where it is today, but I actually studied AI neural network theory in college, believe it or not. To me, it was like a perfect blending of all the different skills that are needed to really be where we are today, which is appreciation and network in the cancer field where there's tremendous need for new medicines.
At Lantern, we didn't have a billion dollars, but we had some good ideas and we had the ability to develop an engine to look at very, very specific problems in cancer. And I had the background to help think and guide some of the business decisions. So I came on about five years ago. I think we have a fantastic team that has gone from one indication to now 14 indications.
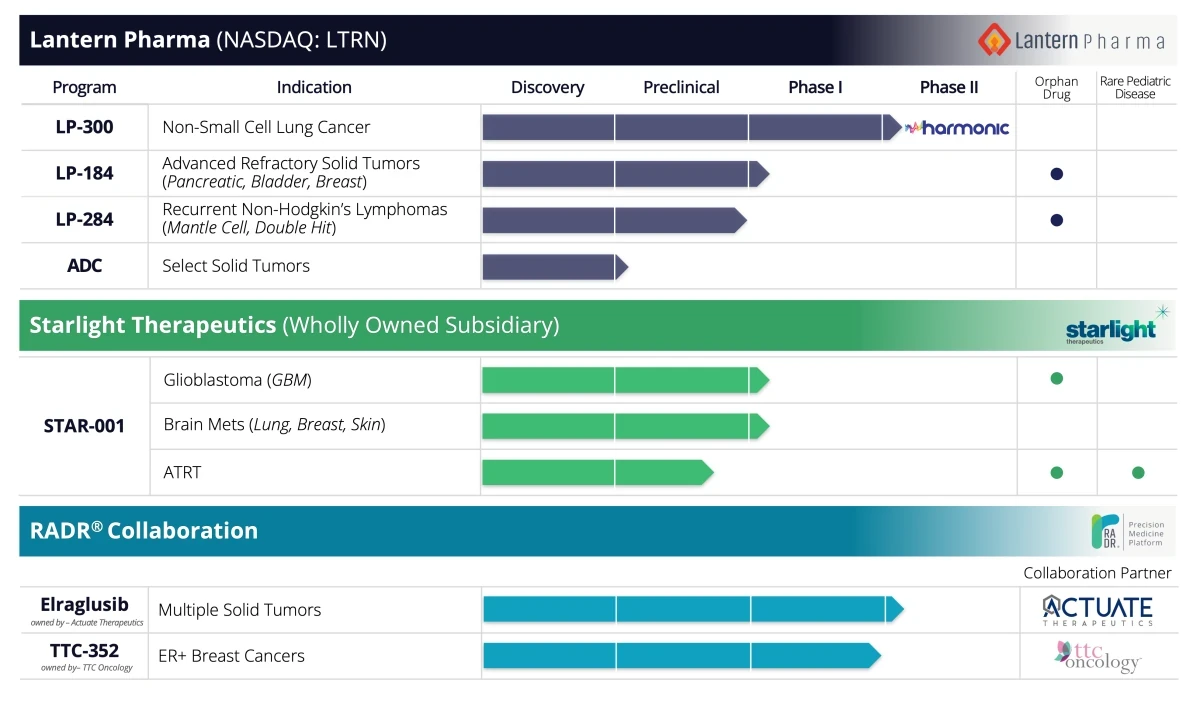
We've got three drugs in clinical trials now. So probably very, very high percentage of programs actually touching patients. We're dosing patients in multiple trials with three different drugs across many indications. And so we're pretty excited by that. And this is all because of the power of using data and AI-driven drug development.
READ ALSO: How AI Enables Precision Oncology
Andrii: That sounds really like you have a sweet spot in terms of skill sets to run this company. Let's unpack this a little bit. As a guy with the actual business background as well, not only scientific background, can you share your framework for building a biotech company, especially clinical biotech company.
Maybe you can share in your example of how Lantern was built, why it is growing, how you managed to pull this off in terms of business. Because science is a great thing, and we will come back to it later in much more detail, but how did you manage to run and grow the company?
Panna: A lot of it is planning, a lot of it is luck, a lot of it is also your own network. I don't know if there's any magic button you can press. You know, we were fortunate to be in funding mode at a time when there was a lot of funding available for biotech, you know, right after the pandemic, there was a real interest in all things biotech. So we were able to hit the market at the right time.
And we made some of the good decisions. We had a lot of decisions to take money privately versus publicly. And I think at the time, the cost of capital for us publicly and the amount of control that we could exert over the business publicly versus privately was better for us. And I remember that was a real moment when we got to sit down and say, okay, we're gonna take a public round, which looks maybe iffy, but it looks positive, or are we gonna take a much smaller, potentially at the time, much more dilutive private round?
We also had a lot of really good, smart advisors and that really helped. And I had wonderful bankers and lawyers that I worked with over the years. So, you know, you got to take lots of input as CEO. You're gonna take a lot of input and you're gonna read the cards of what's going on in the market.
But ultimately you have to have that expectation of, where is this funding going to take us? Because interesting science takes big funding. It takes big funding and it takes the ability to make decisions that can be really, really tough. So you wanna make sure that whatever decisions you're making, you're not gonna lose your focus on the end goal and make sure that people that are lined up with you, in trying to drive that shareholder value or build the base of value are going to be mindful of what the end goal is because if you don't have that then you're going to run into challenges and that's across any company not just biotech.
Andrii: Good points! My career started as a researcher and I have seen so many academic labs which would produce some kind of cool results. But then when they would start an actual spin-off, or a VC startup, they would never take off for some reason. And so I realized that it is so important to take care about the business side, the financials, all these kind of organizational aspects versus just cool science.
Panna: Yeah, you got to do both. You know, you can't have mediocre science and really good business and expect it to be a winning equation. It can be, but it's not guaranteed. And you can't really have mediocre business and great science. So you got to really try to bring both together. And then the timing has to be right. We really are at a time where I think even big pharma really sees that.
AI and computationally driven approaches to drug development are making a difference. You know, they haven't jumped in 100%, but they're all dipping their toes in the water. But even in this space, you know, there are a lot of, I would say, there are a lot of little favorites, you know, so I always think innovation really is going to come from the outside. And if you look at industries like finance and semiconductors and tech, they have different regulatory pressures than of course drug development. But a lot of that innovation, it didn't come from inside the four walls of all the big companies, it came from outside. And so I think we're beginning to see people accepting AI, but it's still somewhat muted. They want their own people doing the AI. They want their own ex-executives running their companies. That's what they're comfortable with.
But really, I think we're at the very early stages of AI just transforming this industry. We can't have 400 or 500 different cancer types that we know and only 90 drugs. So there's a wide open space. And so I think we really want to shape Lantern to try to be a pioneer in the rapid development of therapies, cancer therapies, with some novel data and AI driven approaches.
And where we are today is so different for a small company than where we were even three years ago versus five years ago. The computational power of things that we can do today is just continues to increase. And when we can look at thousands and thousands of molecules in an afternoon and characterize them and generate new molecular features on them in a matter of hours that, you know, things you couldn't even imagine doing some 10 years ago.
So this kind of improvement in output yields improvement in the cost structure of developing drugs. And it also improves the ability to make more, I would say, precise and guided design of validation experiments in animals and eventually going to trials.
And so this is really important because then all that data comes back to the life cycle management of that molecule. Thinking about new indications, thinking about combinations, all that stuff is very important. And the earlier you can determine that in the development of the molecule or the drug, you know, I think the greater confidence you'll have when talking with pharma partners, but also with your investors. And that really hasn't happened until very recently.
Oftentimes you'll even see, even when we look at historical trials of some compounds, you'll see people went head first into phase one or phase one B, and they really didn't fully understand the molecule yet, which is surprising to me. And so now that's changing. You're seeing companies like ourselves and other great AI driven companies that they really understand the molecular features, mechanisms of action, potential combinations, much earlier in the life cycle of the program, which is, I think, really needed.
Andrii: This brings me to my next question about the platform companies, because I have read a nice article the other day on Substack. It was about the different kind of business models for the biotech, like regular business model, the asset-centric business model, revolving around one or several molecules. This is is a very straightforward business model.
But then there is this platform-companies model, a rising trend, which is technology enabled business model, essentially, where you can have a lot of molecules very early on with pretty high quality, using things like AI or some other technologies. And the business model for growing platform companies is very fundamentally different in many ways. Can you comment on that?
Panna: That's a great question. There's always a tension between are you a platform company constantly spinning out new ideas, or are you asset-centric focus company? And at Lantern, we're really unique in that we are, I think, right down the middle. We have developed assets that we either are de novo, first in human molecules, or rescue drugs that have never seen approvals.
And we have both types of compounds now in clinical trials. Our plan, our business model is to take those through early stage trials, phase 1, phase 1b, phase 2, and then license or partner those out. We're not gonna go to an approval kind of in our current form and shape.
You know, running phase three trials and going to commercial approval and the final gauntlets of the market launch, that's what Pharma is actually good at, unfortunately or fortunately, right?
What we're good at is we're good at innovating. Like you said, we're platform-centric, but we do wanna develop the asset because that's where you can milk the most amount of value. So you can get at some really good phase one and phase two data. I mean, then the molecule has a lot of legs on its own. And I believe that if we really, really believe that AI will solve a lot of the challenges in developing molecules, well, we should eat our own dog food.
We should go ahead and develop that molecule, right? I mean, you're just sitting there and spinning out new ideas and new chemical structures, new pharmacophores and new agonist classes and new ideas. Well, any company can do that nowadays, unfortunately, or fortunately. And some can be more disease-centric and some can have certain features, but just spinning out compounds is I would say is interesting, but it's not solving the problem.
The problem is you have humans dying of lots of different diseases that we're able to cure. So our joy as a company, our mission is really to affect patients and get them medicines faster and cheaper. And so for us, we want to eat our own dog food and get those medicines out and actually reap the rewards. But we want to do it in an AI driven model.
You hear a lot of companies saying, well, AI is going to solve drug development, but they're not doing any drug development. They don't have a single patient dosed. And so that I always wondered, well, at the end of the day, what really are you doing?
And so yes, we will license or partner our assets out, but we want to know firsthand that they're safe in human, that they're effectively doing what we think that they're going to do, and that they have a promise to change the curve. And there's a great trial now that we just started, a first in human molecule that works across a wide range of tumor types. And three years ago, when we took the company public, you know, this wasn't even manufactured yet. So we went and manufactured it. We've got multiple orphan indications. We've got, I don't know, eight or ten different publications on LP184.
It's a novel, synthetically lethal DNA damaging agent. And it's exquisitely sensitive in cancers that have certain deficiencies in DNA damage response. We know the mechanism of action in terms of when PTGR1, which is the enzyme that drives this to really be a super potent molecule. And it's gonna work in a wide range of cancers, but particularly some of the more aggressive cancers like pancreatic and brain ones.
And we're pretty excited by it. So it's in a study now. We're using a Bayesian design to evaluate the safety and tolerability. And we're now in later stage cohorts. And we'll have some data, I think, in the first half of 2024. And I think this will be a wonderful example of how we went from.
concept all the way through manufacturing, all the way through all the IND filing, getting big KOLs on board like Dr. Igor Astrosov at Fox Chase Cancer Center, Dr. John Lutera at Johns Hopkins, and we're dosing humans.
We have another drug, LP300. That's not our first in human drug. It's a drug that we bought the rights to. It was a failed drug in a phase three on multiple continents. We thought that there was a potential for this molecule to be combined with two different existing standard of care chemotherapies and then introduced to a subset population of never smokers.
And never smokers have a very, very different molecular profile when they get non-small cell lung cancer. Totally different. They don't have the major common oncogene mutations. They have very, very low tumor mutation burden. They don't have mismatch repair genes. So there's a very, like a profile, it's like night and day, but they still have non-small cell lung cancer.
So the cancer manifests itself in the lining, the adinocarcinoma, but it's totally different molecularly. And this drug seems to work and improve the outcome in historical trials and actually change one of the most important things that you can't change in retrospective studies, which is overall survival. And it changed the overall survival by 25% to 100% in never smokers, because never smokers had the molecular profile for this drug to work.
So we bought the rights to it. We relaunched the trial. We've gotten some really exciting response from some patients and the trial enrolls slow because we really have to educate clinicians about the never smoker versus smoker difference. And as probably a lot of people know, non-small cell lung cancer is a very, very crowded space.
In never smokers, it's not that crowded. So again, we're taking the power of not necessarily, hey, let's design a cool new ATAR agonist with a cool pharmacophore that spins this way, but this is actually taking an existing molecule that's not in favor of Vogue and saying, how can it really work?
You know, why was a subset of data exquisitely interesting? And then using molecular modeling and all this genomic data that we have today that we didn't have when the drug failed 10 years ago or eight years ago and saying, okay, why does it work? What's unique about this subset of patients exploring that, proving that out in very targeted models, including animal models, and then relaunching it into a trial.
So this combination of different approaches to me is really what should drive AI-driven drug development is that the technology is wonderful, but the technology and capabilities pointed at solving real human problems is what's really exciting.
Our mission is not, hey, let's build the coolest widget. Our mission is let's build really cool widgets that solve problems in cancer. Right, at the end of the day, we are really focused on cancer, which gives us somewhat of an advantage because we're not looking at all different types of diseases like some of our peers. Some of our peers are looking at everything from neurodegenerative to metabolic to cardio to autoimmune to rare disease to cancer.
And so we'd like to, you know, I think we don't have enough money to do that. But secondly, I think by having focus, you de-risk and you also accelerate your knowledge, like our insight and certain classes of drugs and certain types of cancers has really matured tremendously. And we can use we can think about how to use that to further de-risk our development. So I think our focus only in oncology can be limiting, but it's also very exciting because it gives us a depth of knowledge that gets implemented back into our AI programs.
Andrii: What you just said, Panna, about the artificial intelligence actually very much resonates with my thinking. Now everybody's talking about de novo drug design, all this kind of generative capabilities, whereas in my opinion, the strongest AI power as of today is to solve multi-parametric optimization problems and basically search the needle in a haystack.
AI can search it using different types of data, using multimodal data, and that's where the power lies. It should not be a new rock star molecule, probably. It should not be otherworldly molecule. It needs to be a molecule which fits to where it needs to fit essentially. And that's what AI is doing. It seems like Lantern's approach is exactly to apply this AI power, computational power to fit the needs with the right molecules. So it's a search problem rather than a de novo creation problem. Am I right?
Panna: Yeah, I think that's definitely as you talked to, using a multimodal approach is really kind of our model, right, is to use molecular structure data, biomolecular and biomarker and genomic data.
Also prior knowledge graphs or networks if they exist, and use all those together to understand compound sensitivity in very specific subtypes. And again, that becomes its own kind of multimodal problem because you can have something that works really well, let's say in melanoma, but doesn't work at all in liver or colorectal cancer, even though they're histologically defined the same. And then you could even have other complications because maybe now, you know, certain cancers become drug resistant faster and generate PGP pump issues versus other cancers.
And so it's constantly you have these layers of multimodal complexity, much like you're saying. And every time you have that, you have new biomolecular features of the cancer. This is something that I think a lot of early drug developers don't understand. They think that a cancer is the same, but you know, cancer has changed a lot.
By the time, you know, your drug is getting to that cancer, is it really going to be what you thought of in that data set that you downloaded from Broad or NCI or GDSC? Probably not. And then also, you know, like you said, these new rockstar drugs, that's great if you can come up with them. They're hard to come up with. We have one of them right now called LP-284. We'll hear more about that next year.
But the challenge is that you're going to probably have to use your drug in combination. Again, going to these multi-parametric decisions. Do you give your drug first? Do you give the other drug first? Do you give them together? Do you have a different type of dosing scheme? Is it metronomic? Do you give a lot upfront and then do a different kind of maintenance period? Really these are perfect problems for computational biology.
And oftentimes you're right, they're not the problems that people think are exciting, but these are the real world problems, right? And so I agree with you, generative AI is great, but you can apply generative AI techniques to lots of different classes of problems, not just engineering new molecules with certain features, which is cool. I think that's very cool too. But again, like you said, going back to our mission, our mission and motivation is to solve cancer in patients.
And so every time we think about, okay, where do we apply our focus? Our focus is going to, can we get this molecule into a targeted and defined patient population? Where are we going to make a meaningful difference? Versus, hey, let's create a new class of, I don't know, the next latest class of covalent kinase inhibitors that do X, Y, Z. Sure, we could try that, but that's not gonna get us to patients.
So that's always one of the key things is that small companies, again, going back to you, you have to really make sure that people are aligned with the mission because when you hire the engineers and data scientists and everyone, they do want to create all kinds of advances that are in their head. But you do have to step back and say, is this going to help us get to patients? Is it going to help us with the pharma deal? Again, those core characteristics, which you think are needed to drive that business. So we're still a small company. We're 25 people. So we have to be maniacally focused on those co-characteristics.
I don't have a team of 200 people like some larger AI companies, but we have a pipeline that's more advanced than most of those companies. And that's because of the focus in specifically oncology, focus in specific types of drugs, and the focus on marching toward the clinic as quickly as possible.
Andrii: Well, this sounds really interesting and logical. And as I understand, in order to be able to work as efficiently with clinical trial business model that you have, like taking existing molecules and essentially fitting them to the right clinical trial patient populations, and this requires really stellar understanding of the biomarker space and, as far as I understand, biomarker-led clinical trials is essentially at the cornerstone of your whole approach to solving cancer.
Can you explain what's the current state of biomarker-led clinical trials and how the things are progressing and what are maybe some challenges as well?
Panna: I think the biggest challenge remains, and it could be biomarker guided or other clinical features. So look, for example, never smokers, there are definitely biomarkers that are more associated with never smokers, but are they widely available and characterized in the clinical setting? The answer isn't always yes, right? So sometimes you have to rely on certain clinical features, in our case, it's just being a never smoker.
Right, that's the number one, you know, so do you have a tyrosine kinase mutation that's no longer responding to existence TKI therapies? Yes, that's a clinical feature, but also a biomarker feature, but it's a little bit of both, right? So, you know, when we talk about biomarker, it's really using whatever biomarker or clinical information to guide the patient selection. And so I think one of the challenges is to correlate biomarker data to actual clinical features.
And that's, you know, not everyone that has a DNA damage repair deficiency tumor is going to stop responding to chemotherapy. But, you know, in the idea, in the cancer biologist who sits in a lab that's a foregone conclusion, right?
So there's, you know, making sure that clinical features and whatever biomarker data you have, have some kind of alignment, and that alignment is greater than 70-80%. That's really a good signal there. You're never gonna have one-to-one perfect alignment, no matter how hard you try to achieve it.
So that's one of the challenges is to get that alignment. What alignment are you comfortable with? Which level of risk are you comfortable launching with? And that's part of it is linking predictions and doing some matrix factorization. But at the end of the day, you have to have a lot of patient data and a lot of these indications that we're going after, there's not a lot of data because these questions haven't been asked in the past.
You know, what's your ERCC level or what's your PTGR1 mapping? So a lot of this stuff, you have to have the right way to validate some kind of clinical measurement with what your animal or in vivo or PDX models have indicated. And that's tough. That's very tough. Now, in highly characterized areas, like, say, CML or Philadelphia chromosome, it's a lot easier. And that's why we've seen a lot of really exciting ADCs with the trastuzumab, you know, the herceptin as one of the antibodies, because there is that generalizable molecular interaction and molecular structure that allows us to make decisions.
But a lot of the new areas linking what you're looking for with actual patient data is a challenge. And so one of the things that we try to do is we try to create what we call these reactomes. And that's really one of the cornerstones of how we approach things is, what is the reactome like around the biomarker? Because oftentimes the biomarker will be a lagging indicator of something and it may or may not be measured.
We have to ask ourselves, is this just as a result, as a lagging indicator? Is it a driver or is it a passenger? Or is it part of the wreckage that happens in the cancer afterwards? And so what we try to do is we try to create kind of network-based reactomes independent of our thinking about our drug and then say, how will our drug react to that in that reactome or in that setting.
And we use both genomic and chemical features to try to make that prediction. We'll not always be right, but if you can be more right than wrong, that helps you. So that's another challenge.
I think the biomarker world has relied largely on tumor genomics and tumor transcriptomics to date. We're seeing the introduction of more protein or multimodal, multiomic approaches, but it's hard then to put those multiomic approaches into the hands of clinicians.
Clinicians don't, they just don't want to have that discussion. It is a complicated discussion. There's a significant challenge of teaching clinicians kind of these multiomic approaches and trying to help them understand what the data is that you're asking for.
And then of course, in the real life setting, asking patients for more blood or more tissue sample when they're third line and they're battling cancer for the third time or three years later, it's tough. You're not gonna get that data.
And so a lot of clinicians want to say, well, this is great, you're going after this subtype of a subtype and this biomarker condition, but I won't even know that for three weeks or four weeks. And so for four weeks, what am I supposed to do? I'm not supposed to tell this cancer patient I'm not gonna do anything.
So those are the challenges, the challenge, they're real challenges. One is obviously in developing the models, one is in making sure you have confidence between clinical features and the biome data features that you have, and then ultimately it's in the clinical setting you have challenges in both educating clinicians and then also involving patients the right way.
And so we can not solve all those problems at all, but we can solve what we can solve, which is create interesting new drugs in patient populations that have a need and then try to convince clinicians and patient advocacy groups that this is a needed option in their cancer battle.
And so if we get a couple of those done and partnered out, I think we'd be very successful. And then we can take our generalizable approach and do it to more cancer compounds. That's our hope, right? Get one or two wins, partner those with pharma and then plow the winnings back into the next generation of compounds.
And we want to constantly keep that innovation cycle going and hopefully get a little bit larger each time so that we can solve more problems. I'd love to solve some of the downstream clinical problems. But as a small company, we have to kind of focus where our innovation is best, which is earlier in the process. More platform-like than asset-like. But we want to be asset-sensitive and asset aware enough that we can sell the asset for a high premium.
Andrii: It makes a lot of sense. Much as the cancer therapeutics are complex already, you seem to have taken on an even more greater challenge with the brain tumors and CNS cancer discovery. Can you tell a little bit about that and maybe explain some specific challenges with blood brain barrier and all this kind of stuff?
Panna: Yeah, that's a great area. I'm glad you picked that up. So shortly after we went public, you know, we had some money. This is in June of 2020. We had a compound, LP184, that had shown very good, but limited, efficacy in glioblastoma. And one of the reasons we looked at glioblastoma oddly enough was because we did large-scale genomic analysis of lots of different tumors.
And we knew that this drug, LP184, would be particularly sensitive, according to the work that we did, including some CRISPR studies to genetically edit the tumors, that when PTGR1 levels were high, this is specific RNA transcript that's downstream of NERF2 and lots of other things. And whenever PTGR1 was high, the tumor became super sensitive.
We looked at all the different data across all the different tumors in the world. I wouldn't get our hands on where we had high quality RNA transcript data and also enzymatic data, which wasn't always available. And we asked our engine, you know, to categorize them, right? Where has it found the most and which data sets, which data sets are the highest quality, which ones are the most frequent, which ones are the most recent, and then give it kind of a scoring factor. And we were surprised that, it said in CNS cancers.
READ ALSO: AI Breaches the Barrier Towards Better CNS Drug Discovery
And the first time that CNS cancer scored, we ignored it. So this is our own biological bias entering into the equation. Even though the platform, RADR, had CNS cancers as like, I think it was number six, we said, no, we're not gonna explore it. Why? We knew, we did not know if the drug crossed the blood brain barrier.
And we did not know, and you can use those Lipinski’s principles, et cetera, that people understand, but those are only about 65% correct.
And we also didn't know if that driver, why it was coming up with that CNS, because we really didn't know that PTGR1 levels were high in brain cancers. And we didn't know the correlation of PTGR1 to even EGFR, which we did know was high in brain cancers.
So it was just like these couple of unknowns. And we're a small company. We were, I don't even think we were 10 people at the time.
So we parked that and we found some of the tumors that we thought we knew would be high, that we already had a bias toward because of what we knew about the drug, what we knew the cancers, and we started collecting more and more data. So our team was getting larger, we're collecting more data and we were beginning to now do wet lab experiments in many of these cancers that we were gonna pursue.
And so we pile that data back in and about three months later, less than three months later, it was two months, we asked the AI again, and this is when all of our AI work was still somewhat manual. Nowadays, these algorithms don't need to be manual. I don't need to go ask someone. Now these algorithms are running themselves all the time.
But anyway, so we ran it again and brain cancer is still on there. And we're like, OK, we can't ignore it this second time. We can't.
And we weren't enriching for brain cancer. So in the back of my mind, I'd thought that it would drop off because we were getting data on other cancers. We were doing our own wet lab experiments, enriching it with proprietary data.
So I just thought that just the sheer volume of data in all the other would drop brain cancer off the top 10 probably, right?
That's just, you know, looking back, I didn't expect it, but it went up to five. Because in the search, we did come across brain cancer data sets and we weren't gonna say no.
And so obviously we sucked those data. And there were a couple of data sets that were very recent, that were new, that actually measured PCGR1. And so we couldn't ignore it the second time.
We did some blood brain barrier analysis, both in the wet lab as well as in silico. And this is what started our, I would say, our obsession with blood brain barrier, brain permeability prediction.
And it said it would be about 98.6% as good as existing standard of care drug, Temadar or Temzolomide. We said, wow, that's really good. And then we went to the lab and actually it was, and we went to mice and it did get there. And so all measures across from our initial in silico prediction were pretty accurate. We said, well, we have to make this better.
Once we had more money and were further down, we now have some of the best blood brain barrier algorithms in the world. If you'll go to therapeutic data commons, and so you can go there and you can put your code there and you can say how your code performed against their data test set. But we've actually even made more and more improvements. We can extract about 4000-5000 features from any smile structure.
We've trained our blood brain barrier algorithms. We have four or five of them, and we actually also have an ensemble algorithm, and that learns, it's kind of a meta learner, and so we can take all these properties, and again, we also have separate algorithms that look specifically at things like isomers and hydrogen changes and some of the more complex things, and we're like now in the 94%+ prediction accuracy, including some of the really more challenging areas.
But when we found that, that's a separate string that the data scientists and AI people were working on. But as we started looking at all these brain cancers, we said, we now work in GBM, we know that. And it's very sensitive in GBM, and we figured out why. At that time, I remember very explicitly said, I want all of the brain cancer data that is publicly available.
That was like a number one priority. We had over a billion, two billion data points. We scanned them all using what we knew about our drug and we did some very integrated kind of multi-omic approach. And we had some, you know, Bayesian matrix factor on top of that, you know, to allow for some of the gaps that we had in data. Cause data, as you know, biology data, it's not perfect, right? It's not, you know, it's not like consumer retail data, right?
There are lots of like little holes and no one's machines are the same. And we said after kind of normalizing and optimizing and figuring, we had a list of brain cancers that this would work in.
And literally almost every one of the brain cancers that we went, some were adult, some were pediatric.
And when we went to the lab to validate those in cell lines, in PDX models and animals, they were almost always correct. And so we said, wow, this is a really, really unique opportunity.
Literally, as you know, neuro-oncology and CNS cancers have not had a single monotherapy approval in 17 years. And usually these drugs work in one cancer or some subtype, but not in all cancers, brain cancers.
And we have this drug now that works in five or six different types, including two pediatric. And we said, this is a massive opportunity and we can't miss that.
But we needed to fund this separately. We needed to get a team. The needs for clinical trials in neuro-oncology are different. We recently brought on board a chief medical officer that is going to run with this under a new brand called Starlight Therapeutics. We plan on funding Starlight even more this year.
And we've identified five or six brain cancer subtypes and we've published on them and we're pretty excited. And this is the ability of using these kind of data driven approaches, but then rapidly validating in wet labs.
One of our key things is we try to validate not only our own wet lab CROs but with key opinion leaders. Because if a key opinion leader wants to work with the molecule and wants to spend their time, we're going to learn something from it.
So we've had key opinion leaders from Johns Hopkins, from University of Texas, from Danish Cancer Research, from some top institutions that have spent time helping us ensure that the focus of the molecule with its unique kind of anti-cancer properties is really perfected as we go into clinical trials.
And we've received rare indications in some of these rare cancer brain cancers, and we've also received a rare pediatric disease designation.
So we've done a lot of work in parallel, but now that we're launching Starlight, I think it is a great example of a company that literally is born from a data-driven, AI-driven approach.
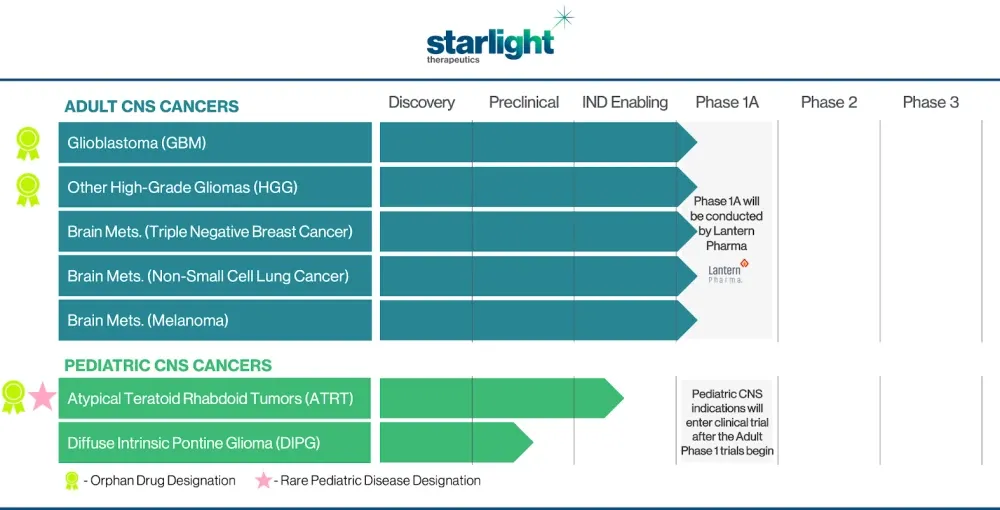
This company would not have existed if we didn't create all these correlations, like you said, these large-scale, multi-parametric questions that were solved and fortunately really were validated in the real world to some extent. So now we are presented with the big challenge, which is let's get it to work in humans.
And so we've de-risked as much as we can. We're gonna raise some money, probably sometime early this year, and we're gonna go into multiple phase 1b and phase 2 trials in these molecularly defined subsets of brain cancers.
And so that'll be Starlight Therapeutics. So I think that'll be an exciting new chapter. I mean, really, it's a great example of an AI company creating a derivative company that wouldn't have existed if it weren't for the data and AI approaches.
And so I think we can do one or two of those companies every couple of years. So that should also be very exciting for our stakeholders. But also the key is in brain cancer, there's enough unique things that are, the trials are more expensive, they're more challenging, they're more imaging intensive, and it's a big, big problem.
And so I think to spin it out, to give it its own focus and its own energy could be a great opportunity for patients, but also to go further faster.
Andrii: This story of how Starlight Therapeutics originated actually is a great example why everybody's so excited about AI. Everybody wants that. When the technology basically opens unexpected new opportunities. That's a very nice case study actually. I have included it in our report The State of AI in the Bipharma Industry, which, I guess, is the unique resource for anyone who wants to really understand the landscape of opportunities and challenges in the AI-driven drug discovery.
I guess with all the molecules that you currently have and the platform capabilities, you are specifically looking for a lot of partnerships. You can maintain, I guess, a lot of partnerships in the diverse areas of oncology research.
Panna: I think the one major area that we're looking for is additional pharma partnerships with larger pharma companies to help take the molecules to where they can achieve their maximum impact on patients. And also we think we can help a lot of large pharma with our computational and data approaches, maybe uncover new things and add value to their program. So that's what we're looking for also in the next chapter of our growth.
Andrii: So this year we're probably going to see these kind of partnerships emerging with Lantern Pharma and other players, I assume. Okay, and maybe something to add on this partnership side?
Panna: When we talk about partnerships, we're typically thinking about partnerships in a couple of categories. You know, first, like I mentioned, we're looking for partners for Starlight. We know that's a big hot area that, you know, companies want a neuro-oncology franchise.
We've been approached by a couple of pharmas. So we're going to look for partners for co-development and or licensing in Starlight Therapeutics.
We are looking for traditional pharma partnerships with our assets that are now in trials. Again, either licensing or co-development or both.
But we're also looking for more generalizable partnerships with our platform. Because we do know there are a lot of really exciting molecules that have been shelved or stopped development, but we think we can probably bring them new life and bring some exciting ideas, whether it be through designing around that class of molecule, designing around the pharmacophore of that molecule, or actually finding new indications for existing molecules.
Those are what I would call more platform centric around our RADR platform. So I think we're looking for all three types of partnerships. And who knows which one will happen first or second, but those are, I would say, the most generalizable types of partnerships.
And who knows, there could be something else that occurs, but those are the ones. We are looking also at some interesting areas that we're just beginning, and we're going to prioritize.
It came out of our planning session, but we found that there's some really interesting overlaps in the autoimmune space. And so we have looked at some interesting things in autoimmune. And so cancer drugs have an interesting, but very mixed history in autoimmune disorders.
And so there's some really interesting insights that we are marching forward on and we'll hear more about that I think next quarter that we're pretty excited about.
And again like you said it's because of these multimodal approaches. You know we have a history of using cancer directed compounds in certain autoimmune disorders. We definitely opened up that playbook a couple of months ago just kind of thinking about it.
And actually we've also, we have some unique insights that we're gonna share probably next quarter, which I think could lend themselves to partnerships because we're not a autoimmune company. We are a cancer company and our expertise will not be in that space. So that also lends itself to potentially partnering.
Topics: AI & Digital