Understanding the Innovations From LSTM, to an Encoder/Decoder Model, to Transformers; and Their Impact on Health Science
AstraZeneca has achieved outstanding results in drug design using large language models applied to SMILES representation of molecules; but what are the steps to understand how this is possible?
In this report, I am going to describe my effort on an LSTM-based encoder/decoder model and on transformers. I would like to show that these technologies are related, can be learnt starting with a simple case, and they are not only relevant for NLP, but also for health science.
On a simple sequence-to-sequence problem, an encoder/decoder model outperforms LSTM, and a further improvement comes from teacher forcing at the cost of added complexity. Next, one needs to understand embeddings: non-contextual embeddings, as in word2vec, and contextual BERT embeddings. And finally one needs to understand the whitepaper ‘Attention is all you need’ that is state-of-the-art for NLP tasks.
The sources I use include video tutorials, experimentation with python code on LSTM, a hands-on training course on Open Source BERT-based models, and an LDA model.
I hope my work can be useful to others who want to gain a deeper understanding on NLP for health sciences.
Encoder/Decoder Models for a sequence to sequence case.
This exercise helps understanding time-dependent neural networks, LSTM and an encoder/decoder model using a sequence to sequence example.
The training videos and code are intellectual property of Prof. Karakaya and are available in youtube and as colab notebooks: [1], [2], [3] . Details on my experimentation are in [3a].
Given a fixed-length sequence, the goal of the model is to predict the reverse sequence.
In [1], the task is done using 2 LSTM layers connected together, and a final dense layer that predicts the highest probability outcome using softmax. The model is implemented in Tensorflow/Keras which makes it easy to define and modify the data flow. It is shown that the predictive performance increases as the information transfer across the 2 LSTM layers increases, while keeping the model size constant. The best results are obtained when the second LSTM layer is initialized with all hidden states for each time step of the first layer, and with the last cell state of the first layer: this is intuitive. It is less obvious that better performance is achieved without increasing the number of free parameters. The exercise shows that information transfer is important, and this is also the case for transformers.
In [2], the model implements an encoder and a decoder, where the encoder is a LSTM layer that creates a context vector. The decoder is also implemented as a LSTM layer that is initialized with the context vector and generates one character at a time. In a loop, token values for successive time steps are supplied, starting with a START token, followed by the output of the token decoded in the previous time step, and the state vector of the previous step, until a STOP condition is met. The decoder feeds the output to the dense layer and softmax for probability calculation.
The encoder/decoder model delivers better performance than the simple LSTM model in [1]. I see it as a stepping stone towards transformers, because this architecture is common with more advanced models.
A further enhancement, [3] calls for augmenting the encoder/decoder model with teacher forcing. At training, the decoder is provided with the right value in lieu of the last-generated value. However, at inference the decoder is provided with the last decoded output as the input for the current time step. It means there are 2 sets of models, one for training and one for inference. This makes it more complicated. Is the better performance worth the added complexity over a plain encoder/decoder model?
For additional insights on teacher forcing one can use [10].
Transformers and BERT
The simplest embeddings are determined using Word2vec or GloVe. These are context-independent [4] but provide a significant advantage over a word vector representation using one-hot-encoding because they have the notion of word distance in the latent space. These embeddings also have significantly lower dimensions than one-hot-encoding.
To make embeddings context aware, RNNs and LSTMs have been used but the temporal dependency among tokens makes the training serial and hence inefficient. They are also negatively affected by vanishing gradients as the sentence length increases. Reverse LSTM can be used to detect context that cannot be otherwise detected, e.g. a left-to-right LSTM cannot disambiguate the word bank in a sentence like ‘the bank of the river’ because the word river occurs after the word bank.
LSTMs support context-dependent embeddings and are the precondition for further progress, and that is why I focused a lot on [1], [2], [3].
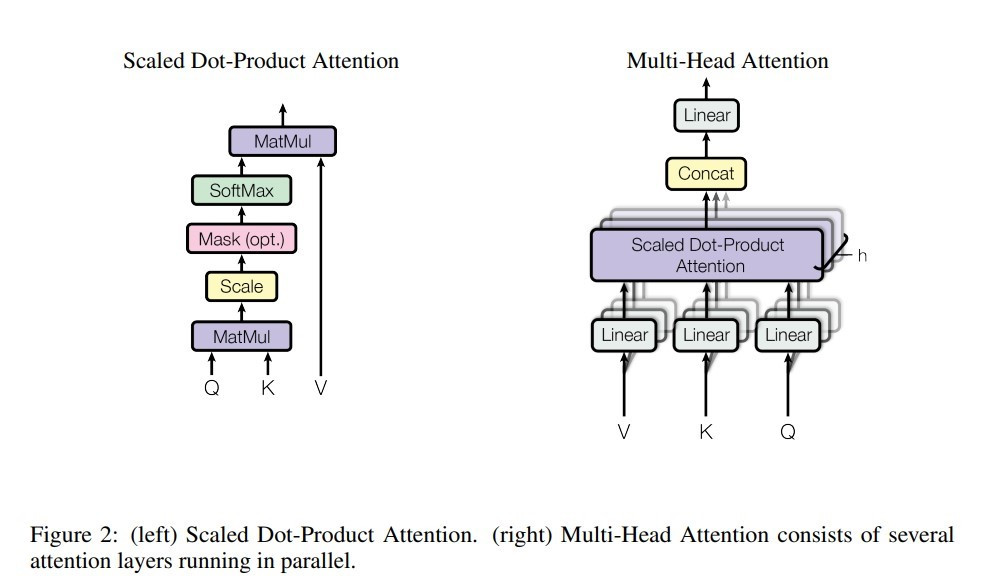
Transformers are the next innovation: each word in a sentence attends to each other word. Using embeddings for the query, key, and value vectors the self attention is built. It contains unknown 2D matrices which are applied to the query vector and to the key vector to obtain vectors on which a dot product is computed. - slides #37-#50 [4]. The dot product result goes into softmax for the probabilities calculation which is then applied to the value vector in order to extract the most likely output token. Similarly to multi layers in a CNN, each with their filters, one defines multiple attention heads, each with their parameters that detect specific facts in the input. Outputs from attention heads are collapsed into a dense layer for softmax calculations.
Transformers can be parallelized in the sentence direction because the temporal dependency of RNN is replaced by the attention algorithm. The complexity is O(N**2), where N is the number of words in a sentence, because each word attends to each other word. Parallelization along the sentence is enabled by GPUs.
BERT
I find [5] very useful to understand the white paper ‘Attention is all you need’. It walks you through a simple language translation exercise, and it highlights how the encoder and decoder rely on self-attention, while explaining the data flow:
-
Start with context-unaware word input embeddings.
-
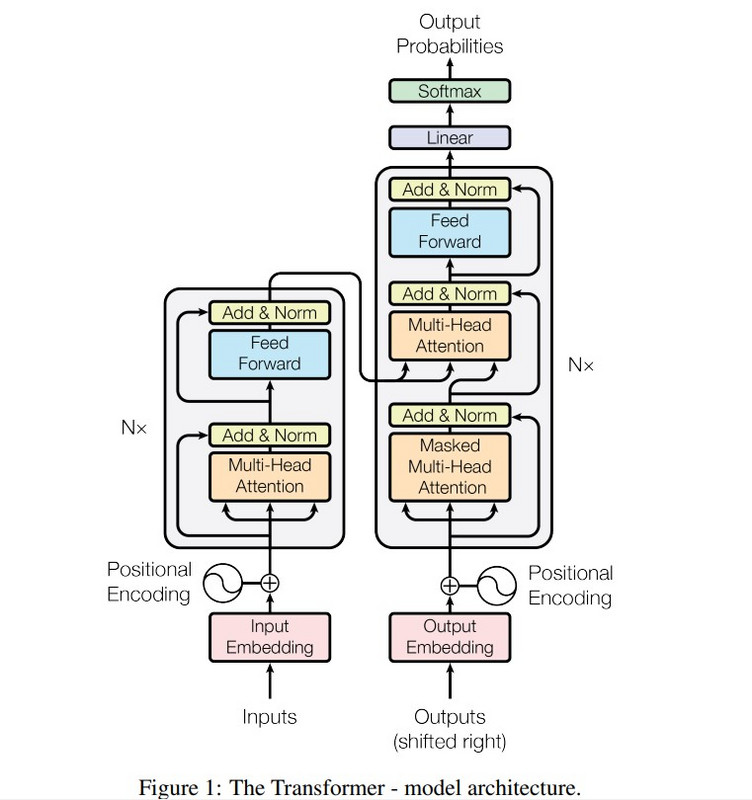
In Figure 1, the left side is the encoder, the right side the decoder
-
Because RNNs are inefficient for long sentences due to the temporal dependencies, the transformer architecture does without RNNs.
-
The translation is created by collaboration of encoder and decoder, which one can learn on a simpler model such as [1], [2], [3].
-
Positional encodings are used to determine the relative position of a word in a sentence, which is mandatory because the attention model does not have a notion of time-sequence.
-
There are 3 attention boxes: one on the decoder side that operates on the input (Figure 1 on the left), one that operates on the partial output (Figure 1 lower box on the right), and one that works on both input and output (Figure 1 higher box on the right).
-
The 3 arrows into the attention box represent the paths of the query, Q; key, K; and value V vectors. Figure 2 shows the details. Courtesy of Google.
-
The FFNN-Softmax layer calculates the maximum probability a token is mapped to the output sequence.
McCormickAI
Further BERT details, as well as an easy to read e-book are provided in [8]. This also helps understanding the model architecture.
Nvidia DLI BERT training
This is an Nvidia Deep Learning Institute Workshop that I attended twice, in 2020 and 2021: ‘Self-supervision BERT and Beyond’.
From word vectorization to Transformers [6]
The workshop explains text representation using embeddings, and it walks you through the technology evolution starting from the simplest model, while explaining the added value in the next refinement: BOW does not encode any semantic information, while Word2vec is the first application of neural networks to embeddings, using a shallow network without non-linearity, which captures the relative distance of (out-of-context) words in the latent space. GloVe refines Word2vec using the probabilities of word co-occurrence, and it is also out of context: using these tools, the embedding of the word bank is the same vector for the financial institute and for the bank of a river.
These embeddings reduce significantly the number of features compared to one-hot-encoding. LSA is one algorithm that relies on Singular Value Decomposition to reduce the problem dimensionality. The performance of LSA can be further improved using a statistical distribution, in PLSA, and in LDA. A discussion about LDA is provided in Appendix.
Another topic of interest is the co-occurrence matrix, although not the main focus of this report. You may view a small example I worked on.
The question arises how to use embeddings in a machine learning model, and several options are reviewed. CNNs may be used: similar to computer vision tasks, one could build a CNN where the initial layers focus on detecting low level features of the input, and the subsequent layers learn higher level features. Embeddings can also be fed into LSTMs, which are more stable than RNNs to learn context-dependent embeddings. And finally, transformers address the shortcomings of CNN, LSTM for NLP tasks. It is also shown that the initial encoder/decoder transformer implementation by Google had RNNs and an attention layer to improve the performance of an LSTM encoder/decoder architecture. And finally, Google proposed in 2017 Attention is all you need, which is a fundamental milestone for AI and NLP.
Hands on exercise using a pre-trained BERT model in a transfer learning scenario
This is an exercise on using pre-trained BERT models for NLP tasks, and it helps understanding the value of transfer learning. The tasks in this workshop are:
- - document classification
- - NER
Document Classification
The document classification uses a pre-trained BERT model and fine-tuning on a custom dataset.
The dataset is a list of medical reports with html-annotations near the text of interest, like cancer, etc; and a label.
The problem is multi-class classification:
- 0 means cancer
- 1 means neuropathic diseases
- 2 means other diseases
The training on the custom data and testing can be done using a python script. The hyperparameters are read from a yaml file, and some are overwritten in the jupyter notebook using Hydra. Therefore one can do the training and testing in one shot using e.g.:
!python $TC_DIR/text_classification_with_bert.py \
model.language_model.pretrained_model_name='megatron-bert-345m-cased' \
model.dataset.num_classes=$NUM_CLASSES \
model.dataset.max_seq_length=64 \
model.train_ds.batch_size=32 \
model.validation_ds.batch_size=32 \
model.test_ds.batch_size=32 \
model.optim.lr=$LR \
trainer.precision=$PRECISION \
trainer.amp_level=$AMP_LEVEL \
model.dataset.max_seq_length=$MAX_SEQ_LENGTH \
model.train_ds.file_path=$PATH_TO_TRAIN_FILE \
model.validation_ds.file_path=$PATH_TO_VAL_FILE \
model.test_ds.file_path=$PATH_TO_TEST_FILE \
model.infer_samples=["$INFER_SAMPLES_0","$INFER_SAMPLES_1","$INFER_SAMPLES_2"] \
trainer.max_epochs=$MAX_EPOCHS
In this example, I use a pre-trained BERT model called 'megatron-bert-345m-cased' from NeMo and modify some parameters to control memory usage (max_seq_length, batch_size), precision (amp_level, precision) and to provide access to the required datasets for training, validation and testing.
After 5 epochs, the model achieves an F1 score of 70 % (harmonic mean of recall and precision)
Named Entity Recognition, NER
In this case, a classifier is built on an existing language model.
The starting point is a domain-specific BioMegatron language model, a model pre-trained on a large biomedical text corpus, PubMed.
The model does not "search" for names from a list, but rather "recognizes" that certain words are disease references from the context of the language.
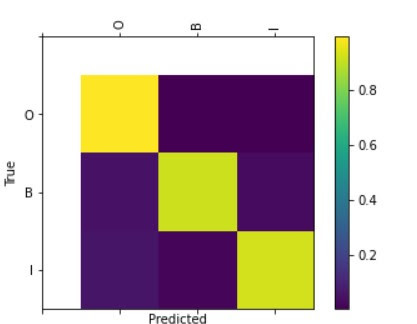
A classifier, working on the BioMegatron language model, is trained on a provided dataset of abstracts, and a label file with annotations signaling the beginning (B), inside (I), and outside (O) of entities within the abstract.
The results are shown below, the F1 score is the second column from right, 98%, and the confusion matrix is also shown:

AstraZeneca
A transformer model [9], coupled with SMILES, is pre-trained on a database containing 1.5 billion molecules, then fine tuned for chemistry tasks that are critical to accelerate drug development.
The model uses the encoder/decoder part of the transformer, and is based on BART which is suitable for sequence to sequence problems. Rather than starting from a generic language model, they make it more relevant for chemistry using data augmentation with SMILES and autoencoders: you can see the architecture in slides #25, #26 of [9]. A further development is MegaMolBART which is the implementation in the Nvidia Megatron framework for scale in Nvidia supercomputers like Cambridge-1.
Similar to transfer learning which is applied to BERT-based models, the pretrained model is fine-tuned for different tasks: synthesis prediction, retrosynthesis, molecular optimization, and property prediction. For example, in molecular optimization, or lead optimization, one can set the required molecule characteristics as input, e.g. non-toxicity, and let the model work out a novel compound that fulfills those characteristics.
Summary
AI and NLP are evolving into large language models with ground-breaking applications in health science: this report refers to AstraZeneca, but there may be several interesting use cases. It also explains my journey to understand some of the components through reading and experimentation. While it is possible for practitioners to use off-the-shelf language models and do minimal tuning, my advice is to also gain a solid understanding of the underlying technology.
Appendix: Latent Dirichlet Analysis (LDA)
LDA is an improvement of Latent Semantic Analysis, which aims at reducing the dimensionality of a corpus using embeddings. Even though LDA is not the primary focus of this report I would like to call out some intuition on how LDA works: a latent layer, the topic, that helps reduce the number of threads connecting words and documents. Luis Serrano’s slides explain the statistical distributions in the model [part 1], and how to train it. [part 2]
An important LDA use case was developed by Booz Allen and Hamilton: NER on EHR to detect adverse events: a target group and a control group are defined, then a vocabulary is filtered out from EHRs using ensemble supervised ML, then LDA is applied using that vocabulary. The result is detection of events that were not evident in the raw data. For more detail you may view the Slides and video. This is an important health science use case for AI and NLP, though off topic relative to the scope of this report.
References
[1] Using LSTM layer in a Recurrent Neural Network, Karakaya Akademi
[2] Basic Encoder/Decoder Architecture Design, Karakaya Akademi
[3] Encoder/Decoder Model with Teacher Forcing, Karakaya Akademi
[3a] Notes on the video and code referenced in [1], [2], [3]
[4] Transformers and Transfer Learning, Google - Turc
[5] Attention is All you need, Kilcher
[6] Machine Learning in NLP, Nvidia DLI
[7] Self Supervision, BERT and Beyond, Nvidia DLI
[8] BERT Research, Chris McCormick - there is also an e-book associated to the videos
[9] MegaMolBART: a generally applicable large-scale pretrained chemical AI model, AstraZeneca, E. Bjerrum - start at slide # 14 -
[10] NLP FROM SCRATCH: TRANSLATION WITH A SEQUENCE TO SEQUENCE NETWORK AND ATTENTION - This is not discussed in this report, however it is a valuable resource to understand the attention model.
Topic: AI in Bio