Google’s AI Auto-Writes Reproducible Research Software for Genomics and COVID Forecasting
Google Research introduced a Gemini-based system that writes and iteratively improves “empirical software,” with a preprint and an interactive site showing full solution trees. The system treats well-defined scientific problems as scorable tasks and targets a single objective metric, reporting expert-level results across genomics, public health, geospatial analysis, neuroscience, numerical analysis, and time-series forecasting.
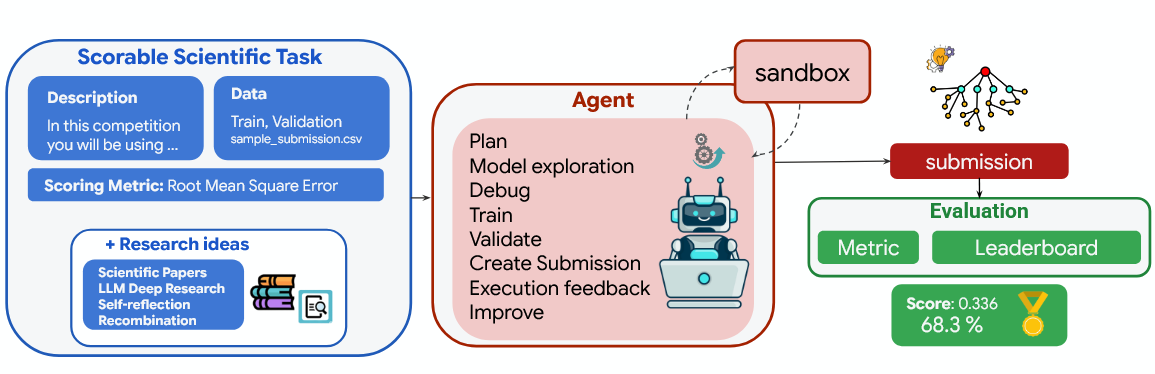
Empirical software here means code optimized to maximize a specified quality score. If a task has a clear metric and data, it qualifies. Users provide a task description, metric, and datasets; the system proposes ideas, implements executable code, evaluates results, then explores thousands of variants via tree search inspired by AlphaZero (Google’s chess engine based on reinforcement learning). It rewrites code using LLM and Tree Search (TS) to return verifiable, reproducible programs. Below is the illustration of the principle - the algorithm is comprised by a code mutation system, where the prompt is enhanced with research ideas, sourced through the search algorithm or a primary literature.
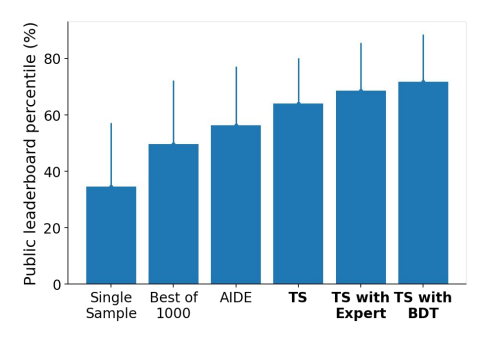
The system was designed to perform highly at the set of 16 Kaggle curated tasks. The scheme below displays the average public leaderboard percentile performance. Methods based on Google’s methods are listed in bold. TS - tree search; BDT - boosted decision tree:
The team put the system through its paces on six very different benchmarks:
- Genomics (scRNA-seq batch integration): Discovered 40 new methods; one combined ComBat and BBKNN to outperform the best published method by ~14%.
- Public health (COVID-19 hospitalizations): Produced models that beat the CDC’s CovidHub ensemble benchmark.
- Geospatial analysis (remote sensing segmentation): Reached >0.80 mIoU with variants of UNet++ and SegFormer paired with extensive test-time augmentation.
- Neuroscience (Zebrafish neural activity prediction): Developed a novel forecasting model that outperformed existing baselines, including computationally intensive 3D video-based models.
- Mathematics (numerical integrals): Correctly evaluated 17 of 19 held-out integrals where standard methods failed.
- General time-series forecasting: Built a general-purpose forecasting library from scratch across 28 datasets (GIFT-Eval benchmark).
The authors frame this as an LLM-driven tree search that rewrites code while incorporating research ideas from the literature, converting software creation into a scored search over executable candidates; because each candidate is evaluated and only score-improving programs are kept, the system can exhaustively traverse alternatives and, in their tests, surpass expert baselines across multiple fields. They report that this compresses exploration from weeks or months to hours or days and argue that in domains with machine-scorable objectives, such empirical software can materially accelerate the rate at which verifiable, reproducible solutions are found.
Paper: https://arxiv.org/abs/2509.06503
Website with visualizations: https://google-research.github.io/score/
Topic: Tech Giants