Sponsored by BenchSci
From Data to Discovery: How BenchSci’s ASCEND Builds a Map for Biomedical Reasoning
Scientific knowledge is expanding faster than at any point in human history, with PubMed indexing over 1.3 million new biomedical articles annually. In parallel, organizations implementing lab automation are generating experimental data at scale.
The result is a vast and growing archive of research, with much of this knowledge inaccessible due to sheer volume, stalling momentum across the discovery pipeline. Such overload drives up costs and raises the risk of missing breakthroughs hiding in plain sight.
Searching KRAS (a gene commonly mutated in cancer) in PubMed, for instance, yields nearly 30,000 results, with over 10,000 of them from the past five years alone. Each paper might contain something valuable—be it a new pathway interaction relevant to target identification, a failure mode in a specific model system that influences experimental design, or a protocol nuance that affects reproducibility, shaping decisions about whether to invest further.
A natural instinct is to throw a general-purpose large language model (LLM) at this corpus; it will return fluent prose in seconds, but its probabilistic output often lacks explainability and traceability underpinning each claim. Most first-generation products, essentially a generic LLM wrapped around a simple retrieval-augmented search layer or PDF summarizer, inherit the same blind spots: they misread ambiguous terminology, may hallucinate facts, and cannot reliably link assertions to primary evidence. Compounding the problem is a mismatch of formats: valuable signals are often buried in figures and supplementary files that most language-based systems can’t read or interpret effectively.
Lacking time, traceability, and synthesis tools, scientists face a data overload that slows discovery, raises costs, and risks missing breakthroughs hiding in plain sight.
What’s missing is an overarching machine-readable structure—scaffolding that surfaces relationships, verifies findings, and supports insight synthesis at scale. Yet that structure remains elusive because scientific data are fragmented across incompatible formats, inconsistent terminologies, and gated access points.
One emerging direction involves combining the strengths of generative language models with structured knowledge representations like knowledge graphs—a hybrid strategy that falls under the umbrella of neurosymbolic AI. By pairing flexible language generation with symbolic reasoning, it offers a way to ground generative AI in structured, verifiable scientific knowledge.
To understand why such hybrid strategies are emerging, it's important to examine where current LLMs fall short in scientific contexts.
Why LLMs Struggle with Science
AI has been a part of biomedical research for years. Convolutional neural networks (CNNs) helped analyze medical and histopathology images, recurrent neural networks (RNNs) enabled early progress in processing scientific text, and models like BioBERT made it easier to mine papers at scale. A major shift came in 2017 with the transformer architecture, introducing self-attention and laying the groundwork for today’s large language models (LLMs).
While LLMs are successful in general-purpose scenarios like ChatGPT, they hit limits that are especially visible in biomedical contexts. They struggle with ambiguity when the same shorthand can signal different concepts — "ER" can mean estrogen receptor or endoplasmic reticulum, while "DEC1" could be misread as a date. Terms like these may cluster near each other due to surface-level textual similarity while they encode different biological roles, leading models to collapse critical distinctions.
This leads into the issue of interpretability. LLMs operate as "black boxes," so a claim appears without an explicit trail back to the experiment that generated it. Some systems have begun attaching reference links (e.g. Deep Research), yet these can still be hallucinated, and the retrieval logic remains obscure—users can see what was pulled, but not why.
Biomedical teams need that trail; every statement must map to a figure, a dataset, or a lab record they can inspect. They also expect the answer to be deterministic (running the query again should produce the same result) and they want enough control to narrow the context when it matters. Because the literature shifts daily, the model has to refresh in step, otherwise yesterday’s output is already old. Without these safeguards, what looks like insight rests on unverifiable ground.
The larger issue is that the scientific corpus isn’t built for machines, and its quality shapes both what models can learn and what they produce. The global scientific library is not a unified body of knowledge; rather, it is a shifting landscape—part archive, part conversation—marked by evolving claims and unstable terminology. Many findings turn out to be wrong, and a language model has no way of knowing that.
As noted earlier, the problem, besides volume, is fragmentation. Key information may be tucked into nonstandard formats across figures and supplemental files, with fragments that resist parsing and rarely connect in ways that AI systems can interpret.
Even within the text, reliability varies because some findings are later revised or withdrawn, while others stay in conflict without resolution. LLMs trained on this material inevitably inherit both its insights and its blind spots. This makes narrow benchmarks and proof-of-concepts, which are often restricted to single use cases, unreliable indicators. A model may appear competent in controlled settings, yet falter when confronted with the full ambiguity, inconsistency, and scale of real biomedical data.
Still, multiple methods exist for improving the utility of LLMs in biomedical research. Domain-specific fine-tuning can adapt models to local vocabulary and concepts, while retrieval-augmented generation (RAG) systems allow models to ground responses in original source texts. Yet these approaches, while helpful, have clear limitations. Vector-based RAG lacks structured semantics, making it difficult to track reasoning paths or resolve ambiguities. Fine-tuning improves language fluency within a domain but does not enforce logical consistency or support traceable claims.
Given the limitations of opaque retrieval logic in typical LLM pipelines, a more robust alternative is the integration of knowledge graphs—structured, symbolic representations of entities and their relationships. Unlike vectors, which encode similarity without meaning, knowledge graphs offer an interpretable world model. They enable both humans and machines to reason over facts, verify origin, and preserve context across diverse data types.
Encoding the Logic of Discovery
Toronto-based deeptech company BenchSci has adopted this approach in its ASCEND platform, embedding structured knowledge directly into LLM workflows. The company’s goal, beyond improving accuracy of biological knowledge, is to augment the researcher’s perspective by building a framework that mimics how a scientist would view and understand biomedical data at scale.
The platform is the result of a decade of work in machine learning and knowledge representation, combined with recent advances in generative AI. This convergence laid the groundwork for ASCEND as a comprehensive system designed to map disease biology at a holistic level previously unattainable with legacy computational approaches.
BenchSci began in 2015 with a focus on extracting experimental evidence from biomedical literature and developing machine learning models grounded in real-world scientific data. A key motivation was the high failure rate of experiments, often due to unreliable or poorly contextualized information in scientific literature.
Thus, the company was among the pioneers in applying machine learning to biomedical search and in building sophisticated knowledge representations, now with over a hundred proprietary models developed over the past decade. However, the recent advent of transformer-based generative AI enabled a qualitative leap forward—combining the fluency and generalizability of state-of-the-art LLMs with BenchSci’s accumulated know-how in evidence-grounded data mining and representation.
Because ASCEND’s foundation was built around experiments and the relationships they reveal, it was primed for explainability from the outset. The LLM layer, combined with the knowledge graph, now enhanced that basis with semantic relationships, helping the system describe complex biological relationships and mechanism-level interactions.
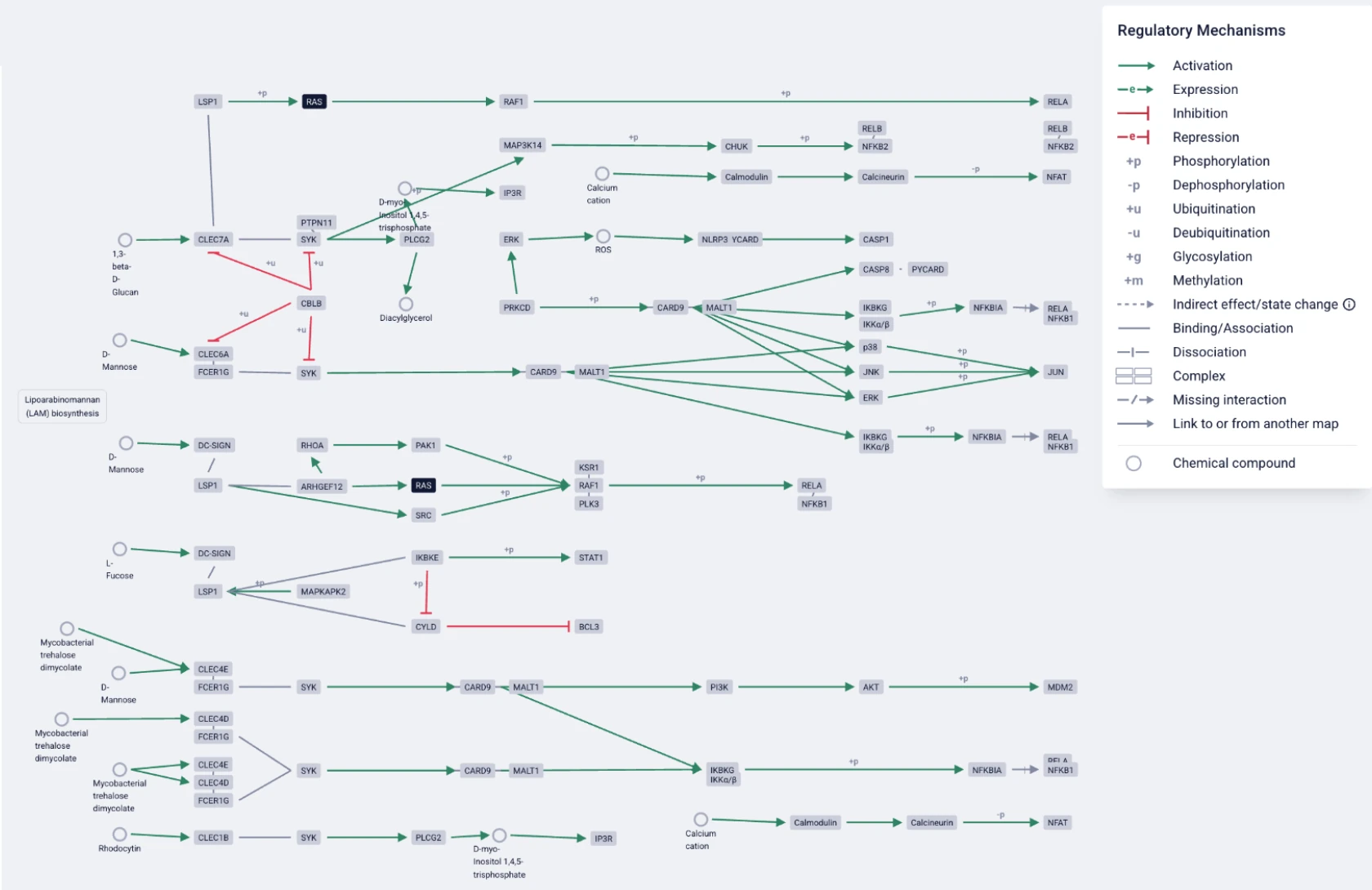
ASCEND is built on a knowledge graph that structures more than 400 million entities and over one billion relationships, providing the evidence backbone for every query and workflow.
Within ASCEND, the graph links facts to reveal their connections, helping to organize complex information and answer specific questions. BenchSci’s knowledge graph encodes relationships between biological entities—genes, proteins, diseases, drugs, reagents, phenotypes—and grounds these relationships in traceable experimental sources. Extracted from scientific publications, preprints, patents, reagent catalogs, and databases, the graph captures experimental evidence in a format researchers can explore, question, and build upon.
Additionally, the graph combines a curated ontological knowledge base with experimental insights to align formats and resolve ambiguities, all with support for multi-hop reasoning across diverse biological contexts.
To construct ASCEND’s knowledge graph, BenchSci draws on tens of millions of scientific publications and a continually expanding body of biomedical data. This includes content beyond what’s typically available through public datasets, made available through legally licensed access to closed-access journals through direct agreements with publishers like Springer Nature, Wiley, and Taylor & Francis.
The graph integrates multiple layers of biomedical data, sourced from:
- Full-text peer-reviewed articles and preprints (e.g., from bioRxiv and medRxiv)
- Experimental figures extracted using proprietary vision-based machine learning models
- Tens of millions of reagent and model system metadata entries, cross-referenced with commercial catalogs and historical usage
- Harmonized biomedical ontologies (like UniProt, KEGG, Human Protein Atlas, MGI, FDA) to ensure consistent concept mapping across datasets
Taken together, these sources form a foundation built to reduce information fragmentation—a common challenge in building coherent biomedical knowledge systems, especially when access to the underlying data is partial or siloed, as remains the case in many efforts to construct similar graphs.
Updated at a regular cadence to keep up with the pace of scientific research, the graph now contains millions of nodes and edges, with a team of over a hundred scientists working alongside engineers to review model outputs and resolve ambiguous cases. Human-in-the-loop curation further strengthens scientific validity, ensuring consistent interpretation and flagging inconsistencies that automated systems might overlook.
Extraction is performed using a fit-for-purpose, best-of-breed approach that applies the appropriate model depending on the use case. These include both text-based and multimodal models that identify and link key elements (e.g. assay type, tissue source, intervention, outcome), grounding each assertion in its source—whether it's in the methods section or embedded in a figure. Unlike generic LLMs, this model mix allows to capture experimental details often buried in visual data and missing from the surrounding text.
BenchSci leverages its knowledge graph to answer scientists' queries to identify relevant publications, trace how a target behaves across different disease contexts, or compare outcomes across model systems, which ultimately enables hypothesis-generating scenarios. Queries are resolved instantly, enabling exploration free from time-intensive manual synthesis.
Towards Platform-Level Intelligence
What BenchSci has built is an evolutionary step beyond the legacy computational paradigm where a specific tool (even AI-supported) would normally be focused on a specific type of problem or dataset. In contrast, ASCEND enables a general-purpose, platform-driven workflow that supports a broad range of scientific tasks, assisting as a copilot designed to be useful in most scientific scenarios.
A user could ask ASCEND: "What immune evasion markers co-occur with KRAS mutations in pancreatic cancer models?"
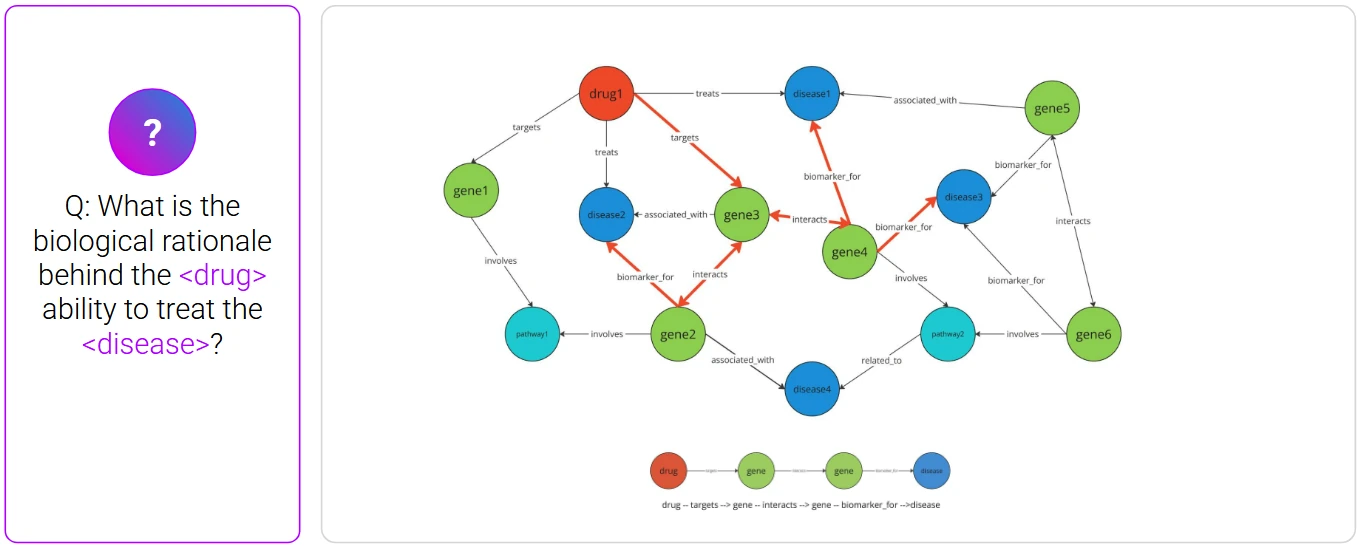
The platform translates this natural language query into a set of graph traversals: KRAS—mutation type—tumor models—immune markers—associated reagents and assay types. In seconds, it surfaces a list of preclinical studies, protocols, and validated reagents, each linked to source documents.
The platform starts by reading scientific papers to pull out key details from experiments—what was tested, how it was done, and what the results were. It picks up on elements like assay type, tissue source, intervention, and outcome, and links them together to form a clear picture of the study.
Since each assertion is linked back to its original source, researchers can easily move beyond summaries to examine findings in their full experimental context. This level of traceability can also reinforce scientific rigor and support regulatory confidence in AI-generated outputs.
But what happens when different papers describe the same biology using different formats or naming conventions?
To resolve this, the same AI responsible for extraction also processes structured and semi-structured content and detects experiment types. It aligns studies even when key elements are labeled or arranged differently.
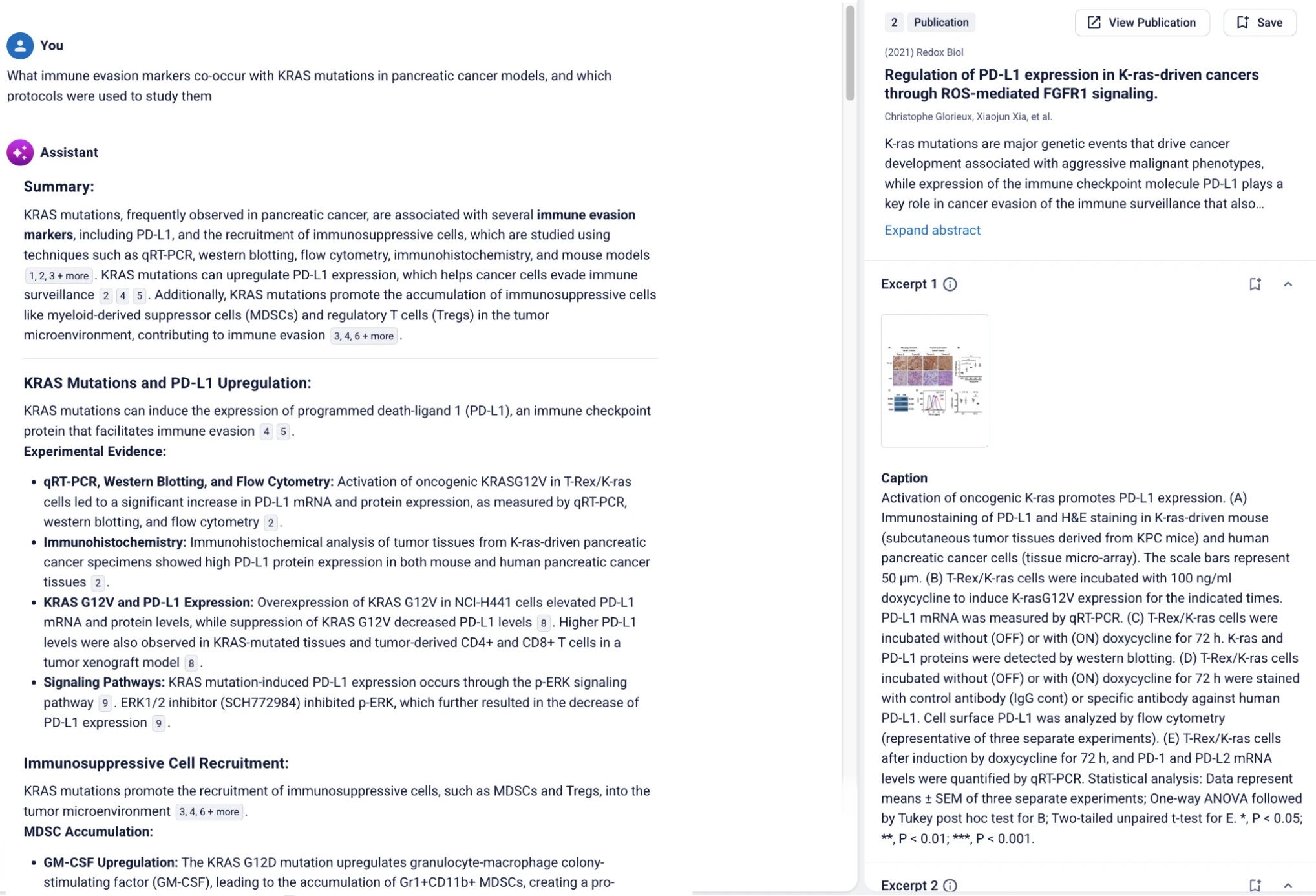
Here, ASCEND’s AI Assistant extracts and summarizes information about the experimental techniques used to study immune evasion associated with cancer. Every statement is linked to a reference.
Each entity and relationship is captured in their Knowledge Graph with properties like biomedical entity type, biomarker type, therapeutic relevance, and preclinical risk factors, and is grounded in their ontological knowledge base (OKB). These labels help highlight targets with potential to translate and flag those that may carry early-stage risk.
Beyond quick retrieval, this lets researchers prioritize targets based on the quality of underlying evidence rather than publication frequency. Queries run in real time and can be filtered by specific parameters like mutation type, tissue, or therapeutic class.
The graph also captures patterns in reagent usage and protocol design. The linkage between experimental methods and their outcomes helps highlight which setups yield consistent results and which tend to introduce variability. It makes it easy to avoid low-reproducibility approaches and wasted effort.

ASCEND can also ingest and process internal data from customers, linking it to relevant research and indexing it so scientists can search and access it alongside other findings.
Because the data are fully structured, they can also serve as input for machine learning workflows. This opens up hypothesis testing or model training while keeping a direct connection to source data. Models built on this framework are easier to interpret and can be updated as new evidence becomes available, offering more transparency than typical LLM-based systems.
ASCEND’s knowledge graph structures biological data to create a reusable, scalable resource supporting decision-making throughout the R&D pipeline.
Today, every team in pharma builds its own view of biology—spending months duplicating searches, manually curating data, and resolving the same ambiguities in isolation. ASCEND flips that model: it externalizes biological reasoning into a shared, structured resource that compounds in value over time. Every query, every resolved entity, every curated edge becomes part of a living map that reduces redundant work, accelerates target triage, and de-risks experimental design.
To operationalize this, ASCEND lets teams curate findings into project folders, generate shareable reports, and anchor outputs directly to source data. Scientific liaisons guide teams through structured onboarding and tailored training, ensuring tools land in context. Organizations may track progress using metrics such as time-to-insight, reproducibility, and the pace of movement through R&D stages.
Here, the knowledge graph becomes more than a reasoning layer—it evolves into a launchpad for predictive capabilities and agentic workflows, enabling AI to interpret data and proactively shape scientific direction.